Turning the corner
It’s a little hard to believe that it’s been only fifteen months since we shipped our first product. It’s been a hell of a ride; there is nothing as exhilarating nor as exhausting as having a newly developed product that is both intricate and wildly popular. Especially in the domain of enterprise storage – where perfection is not just the standard but (entirely reasonably) the expectation – this makes for some seriously spiked punch.
For my own part, I have had my head down for the last six months as the Technical Lead for our latest software release, 2010.Q1, which is publicly available as of today. In my experience, I have found that in software (if not in life), one may only ever pick two of quality, features and schedule – and for 2010.Q1, we very much picked quality and features. (As for schedule, let it be only said that this release was once known as “2009.Q4”…)
2010.Q1 Quality
You don’t often see enterprise storage vendors touting quality improvements for a very simple reason: if the product was perfect when you sold it to me, why are you talking about how much you’ve improved it? So I’m going to break a little bit with established tradition and acknowledge that the product has not been perfect, though not without good reason. With our initial development of the product, we were pushing many new technologies very aggressively: not only did we seek to build enterprise-grade storage on commodity components (a deceptively daunting challenge in its own right), we were also building on entirely new elements like flash – and then topped it all off with an ambitious, from-scratch management stack. What were we possibly thinking by making so many bets at once? We made these bets not out of recklessness, but rather because they were essential elements of our Big Bet: that customers were sick of paying monopoly rents for enterprise storage, and that we could deliver a quantum leap in price-performance. (And if nothing else, let it be said that we got that one very, very right – seemingly too right, at times.) As for the specific technology bets, some have proven to be unblemished winners, while others have been more of a struggle. Sometimes the struggle was because the problem was hard, sometimes it was because the software was immature, and sometimes it was because a component that was assumed to have known failure modes had several (or many) unanticipated (or byzantine) failure modes. And in the worst cases, of course, it was all three…
I’m pleased to report that in 2010.Q1, we turned the corner on all fronts: in addition to just fixing a boatload of bugs in key areas like clustering and networking, we engaged in fundamental work like Dave’s rearchitecture of remote replication, adapted to new device failure modes as with Greg’s rearchitecture around resilience to HBA logic failure, and – perhaps most importantly – integrated critical firmware upgrades to each of the essential components of the I/O path (HBAs, SIM cards and disks). Also in 2010.Q1, we changed the way the way that we run the evaluation of the software, opening the door to many in our rapidly growing customer base. As a result, this release is already running on more customer production systems than any of its predecessors were at the time that they shipped – and on many more eval and production machines within our own walls.
2010.Q1 Features
But as important as quality is to this release, it’s not the full story: the release is also packed with major features like deduplication, iSER/SRP support, Kerberized NFS support and Fibre Channel support. Of these, the last is of particular interest to me because, in addition to my role as the Technical Lead for 2010.Q1, I was also responsible for the integration of FC support into the product. There was a lot of hard work here, but much of it was born by John Forte and his COMSTAR team, who did a terrific job not only on the SCSI Target Management facility (STMF) but also on the base ALUA support necessary to allow proper FC operation in a cluster. As for my role, it was fun to cut the code to make all of this stuff work. Thanks to some great design work by Todd Patrick, along with some helpful feedback from field-facing colleagues like Ryan Matthews, I think we came up with a clean, functional interface. And working closely with both John and our test team, we have developed a rock-solid FC product. But of course (and as one might imagine), for me personally, the really gratifying bit was adding FC support to analytics. With just a pinch of DTrace and a bit of glue code, we now have visibility into FC operations by LUN, by project, by target, by initiator, by operation, by SCSI command, by size, by offset and by latency – and by any combination thereof.
As I was developing FC analytics, I would use as my source of load a silly disk benchmark I wrote back in the day when Adam and I were evaluating SSDs. Here for example, is that benchmark running against a LUN that I named “thicktail-bench”:
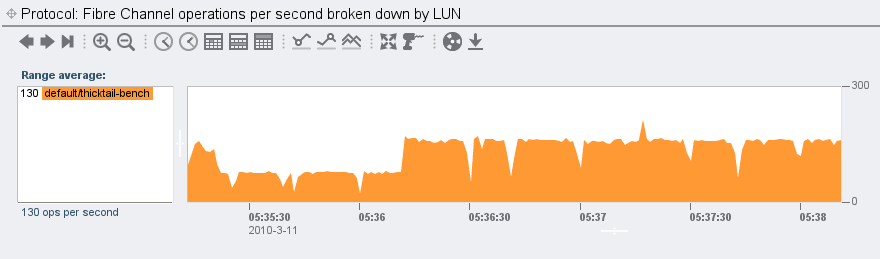
The initiator here is the machine “thicktail”; it’s interesting to break down by initiator and see the paths by which thicktail is accessing the LUN:
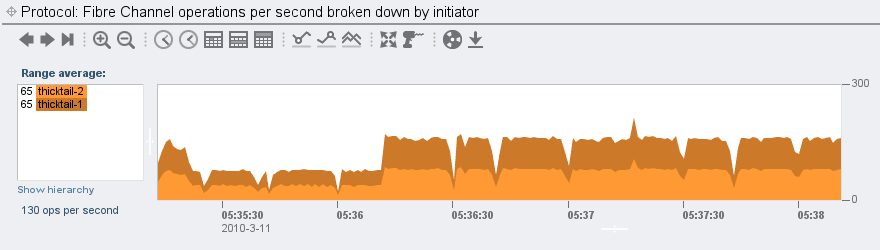
(These names are human readable because I have added aliases for each of thicktail’s two HBA ports. Had I not added those aliases, we would see WWNs here.) The above shows us that thicktail is accessing the LUN through both of its paths, which is what we would expect (but good to visually confirm). Let’s see how it’s accessing the LUN in terms of operations:
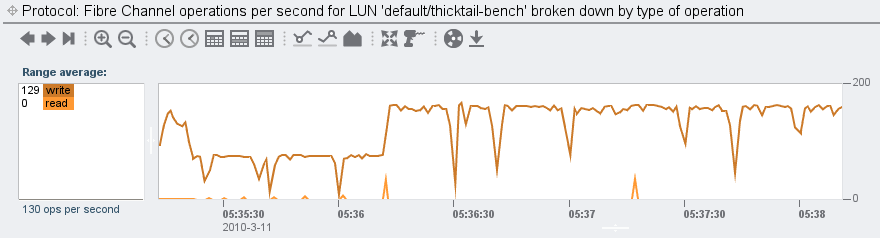
Nothing too surprising here – this is the write phase of the benchmark and we have no log devices on this system, so we fully expect this. But let’s break down by offset:
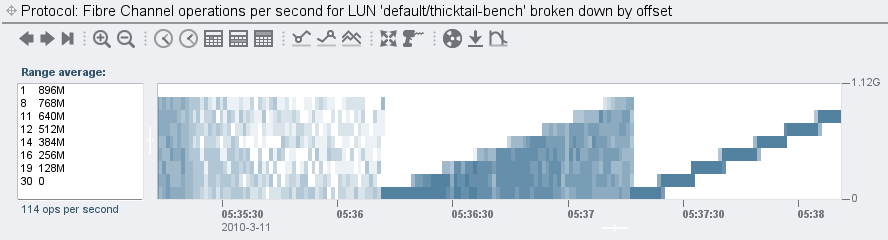
The first time I saw this, I was surprised. Not because of what it shows – I wrote this benchmark, and I know what it does – but rather because it was so eye-popping to really see its behavior for the first time. In particular, this captures an odd phase I added to this benchmark: it does random writes across an increasing large range. I did this because we had discovered that some SSDs did fine when the writes were confined to a small logical region, but broke down – badly – when the writes were over a larger region. And no, I don’t know why this was the case (presumably the firmware was in fragmented/wear-leveling/cache-busting hell); all I know is that we rejected any further exploration once the writes to the SSD were of a higher latency than that of my first hard drive: the IBM PC XT’s 10 MB ST-412, which had roughly 95 ms writes! (We felt that expecting an SSD to have better write latency than a hard drive from the first Reagan Administration was tough but fair…)
What now?
As part of our ongoing maturity as a product, we have developed a new role here at Fishworks: starting in 2010.Q1, the Technical Lead for the release will, as the release ships, transition to become the full-time Support Lead for that release in the field. This means many things for the way we support the product, but for our customers, it means that if and when you do have an issue on 2010.Q1, you should know that the buck on your support call will ultimately stop with me. We are establishing an unprecedented level of engineering integration with our support teams, and we believe that it will show in the support experience. So welcome to 2010.Q1 – and happy upgrading!